这篇文章总结了 Golang 的sync包,包括sync.Map、sync.Once、sync.Pool、其中sync.Mutex的底层通过semaphore机制实现等等。
Go语言里对同步的支持主要有五类应用场景:
资源独占:当多个线程依赖同一份资源(比如数据),需要同时读/写同一个内存地址时,runtime需要保证只有一个修改这份数据,并且保证该修改对其他线程可见。锁和变量的原子操作为此而设计
生产者-消费者:在生产者-消费者模型中,消费者依赖生产者产出数据。 channel(管道)为此而设计
懒加载:一个资源,当且仅当第一次执行一个操作时,该操作执行过程中其他的同类操作都会被阻塞,直到该操作完成。sync.Once为此而设计
fork-join:一个任务首先创建出$N$个子任务,$N$个子任务全部执行完成以后,主任务搜集结果,执行后续操作。sync.WaitGroup为此而设计
条件变量:条件变量是一个同步原语,可以同时阻塞多个线程,直到另一个线程 1) 修改了条件; 2)通知一个(或所有)等待的线程。sync.Cond为此而设计
注意:这里当我说"线程"时,了解Go的同学可以自动映射到 “goroutine”(协程)。
1 sync.Map
1. sync.Map 用法
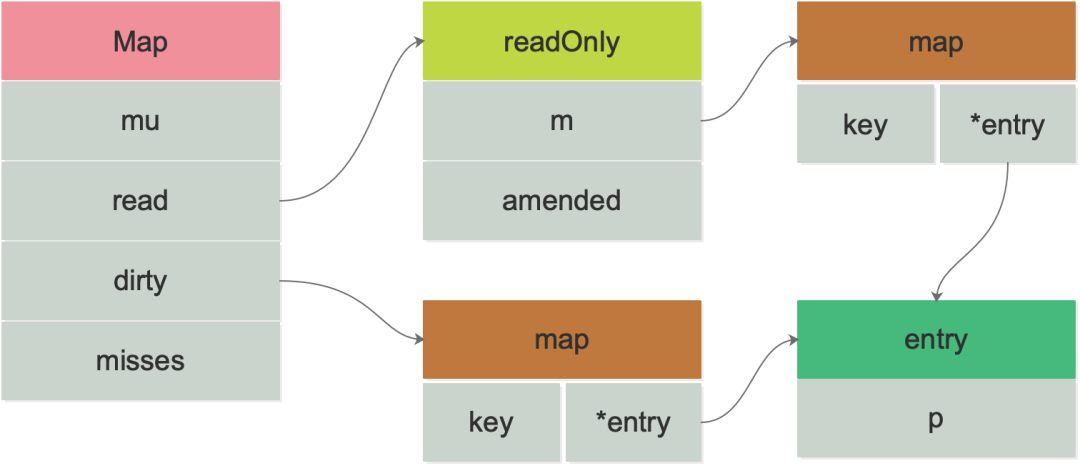
sync.Map是一个线程安全的map结构,一般用于多读少写的并发操作,下图是sync.Map的数据结构:
图1:sync.Map的数据结构
代码结构是:
1
2
3
4
5
6
type Map struct {
mu Mutex
read atomic . Value // readOnly
dirty map [ interface {}] * entry
misses int
}
mu是Map的互斥锁用于对并发操作进行加锁保护read是用于存储只读内容的,可以提供高并发的读操作dirty是一个原始的map结构体,对dirty的操作需要加锁,dirty包涵了全量的数据,在读数据的时候会先读取read,read读取不到再读dirtymisses 是read读取失败的次数,当多次读取失败后 misses 累计特定值,dirty就会升级成read
sync.Map这里采用的策略类似数据库常用的”读写分离”,技术都是相通的。具体例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func main () {
var value sync . Map
// 写入
value . Store ( "your name" , "shi" )
value . Store ( "her name" , "kanon" )
// 读取
name , ok := value . Load ( "your name" )
if ! ok {
println ( "can't find name" )
}
fmt . Println ( name )
// 遍历
value . Range ( func ( ki , vi interface {}) bool {
k , v := ki .( string ), vi .( string )
fmt . Println ( k , v )
return true
})
// 删除
value . Delete ( "your name" )
// 读取,如果不存在则写入
activename , loaded := value . LoadOrStore ( "his name" , "baba" )
fmt . Println ( activename .( string ), loaded )
}
2. 原理结构
Load
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func ( m * Map ) Load ( key interface {}) ( value interface {}, ok bool ) {
// 首先从只读字段读取内容
read , _ := m . read . Load ().( readOnly )
e , ok := read . m [ key ]
// 如果没读到,并且dirty有read没有数据则从dirty中读取
if ! ok && read . amended {
m . mu . Lock ()
// 在从dirty读取前需要加锁后再做一次验证,防止期间read突然有数据,也就是double check
read , _ = m . read . Load ().( readOnly )
e , ok = read . m [ key ]
if ! ok && read . amended {
e , ok = m . dirty [ key ]
// 将此次记录记录添加到miss中,可以看到这里没对dirty的取值做判断,也就是说不管是否
// 取到miss都会添加一次
m . missLocked ()
}
m . mu . Unlock ()
}
if ! ok {
return nil , false
}
return e . load ()
}
Load方法讲解:首先从只读字段read中读取键值的内容,如果没读到,并且amended为true(dirty有read没有数据)则尝试从dirty中读取,不过这里要做 double check, 然后将此次缓存穿透记录一次到miss字段。
Store
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
func ( m * Map ) Store ( key , value interface {}) {
// 存储之前先从只读字段读取要存储的值,如果存在,则用CAS的方式将新的值存储进去
read , _ := m . read . Load ().( readOnly )
// tryStore 会检查dirty的keys值是否已经删除,
// 如果没有删除标记,则直接采用CAS方式存储entry
if e , ok := read . m [ key ]; ok && e . tryStore ( & value ) {
return
}
m . mu . Lock ()
// double check
read , _ = m . read . Load ().( readOnly )
if e , ok := read . m [ key ]; ok {
// double check 如果read存在,调用 unexpungeLocked 将 expunged 设置为 nil,
// 然后更新dirty,expunged 表示dirty中记录的删除标识(read没同步),由于有新的值存储需要
// 将删除标识更新。
if e . unexpungeLocked () {
m . dirty [ key ] = e
}
e . storeLocked ( & value )
} else if e , ok := m . dirty [ key ]; ok {
// 如果read中没有对应的键,从dirty中有则直接更新dirty中的键
e . storeLocked ( & value )
} else {
// dirty 和 read 都不存在这个键的情况
if ! read . amended {
// amended为true标识dirty包含read没有的key,由于dirty是最全的数据,amend为false只有两种
// 情况,一种就是 dirty 的键值等于 read 的键值,一种是dirty为空的时候,所以这里只有可能是
// 第二种,也就是dirty为空,因此再store 之前先判断一下 dirty map 是否为空,如果为空,就把 read map 浅拷贝一次。
m . dirtyLocked ()
m . read . Store ( readOnly { m : read . m , amended : true })
}
// 如果dirty数据和read的key不同步数据,直接将值写入dirty
m . dirty [ key ] = newEntry ( value )
}
m . mu . Unlock ()
}
Store方法讲解:存储之前先从只读字段read中读取要存储的值,在read中存在键值对的时候,则用 CAS 的方式将新的值存储进去,如果不存在则加锁做个 double check,将新数据写入dirty中。如果dirty和read中都没数据,dirty和read的键值不同步,则将数据直接写入dirty, 如果dirty键值数据和read一样,同时dirty为nil,将read浅拷贝一份到dirty,为后面赋值可以同时写入dirty和read。
Delete
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
func ( m * Map ) Delete ( key interface {}) {
m . LoadAndDelete ( key )
}
func ( m * Map ) LoadAndDelete ( key interface {}) ( value interface {}, loaded bool ) {
read , _ := m . read . Load ().( readOnly )
e , ok := read . m [ key ]
if ! ok && read . amended {
m . mu . Lock ()
read , _ = m . read . Load ().( readOnly )
e , ok = read . m [ key ]
if ! ok && read . amended {
e , ok = m . dirty [ key ]
m . missLocked ()
}
m . mu . Unlock ()
}
if ok {
return e . delete ()
}
return nil , false
}
func ( e * entry ) delete () ( value interface {}, ok bool ) {
for {
p := atomic . LoadPointer ( & e . p )
if p == nil || p == expunged {
return nil , false
}
if atomic . CompareAndSwapPointer ( & e . p , p , nil ) {
return * ( * interface {})( p ), true
}
}
}
Delete方法讲解:sync.Map的 Delete 方法本质是用的读取和删除,也就是先读取到数据再对数据进行删除,读的方法和 Load 的方法是一样的。
Range
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
func ( m * Map ) Range ( f func ( key , value interface {}) bool ) {
// 如果amend为ture,说明dirty包含了read所有的key,将dirty提升为read,
// 并将dirty设置为nil,之后用Store存储新的值的时候再拷贝回来
// 最后对read进行遍历即可
read , _ := m . read . Load ().( readOnly )
if read . amended {
m . mu . Lock ()
read , _ = m . read . Load ().( readOnly )
if read . amended {
read = readOnly { m : m . dirty }
m . read . Store ( read )
m . dirty = nil
m . misses = 0
}
m . mu . Unlock ()
}
for k , e := range read . m {
v , ok := e . load ()
if ! ok {
continue
}
if ! f ( k , v ) {
break
}
}
}
Range原理讲解:Range 本质是通过遍历只读字段read得到,为了让只读字段包含所有数据,当dirty和read不相等的时候,将dirty升级为read, 最后再对read进行遍历即可。
2 sync.Pool
1. sync.Pool 用法
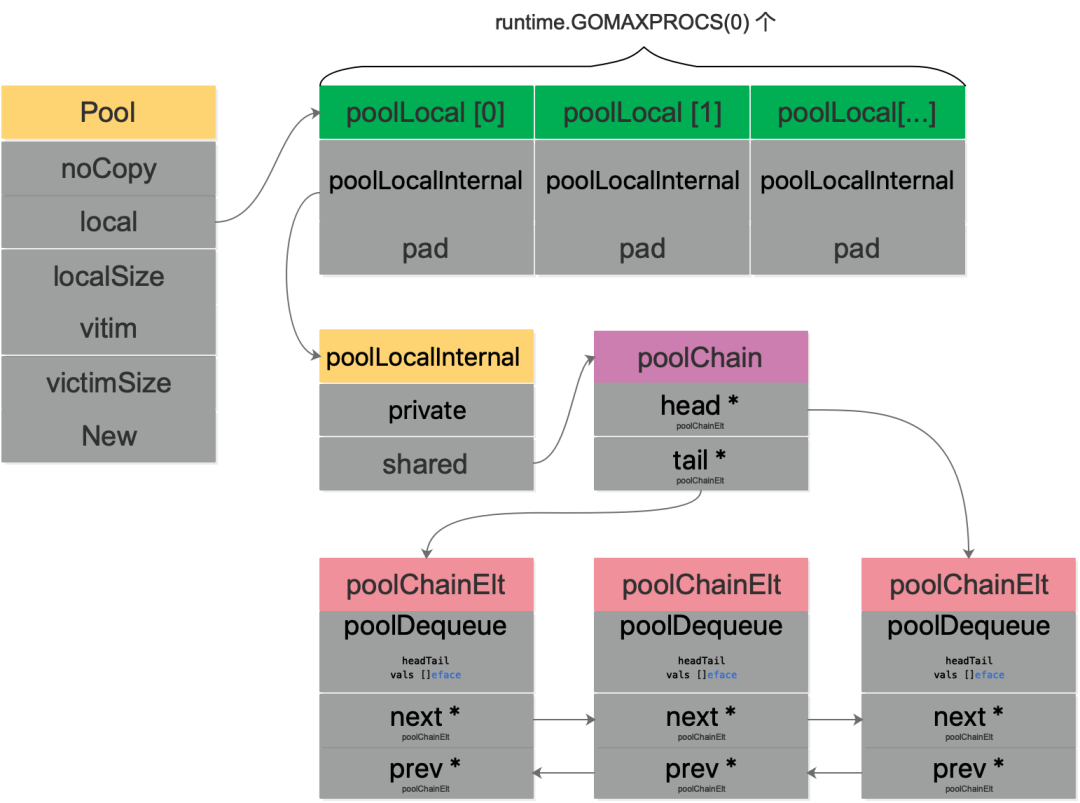
sync.Pool是一个用来缓存大量重复对象,减少大量对象创建给GC压力,是sync异步包中很重要的一种数据结构,看其基本数据结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
type Pool struct {
// noCopy 表示不支持值拷贝,如果出现值拷贝用 go vet 编译检查的时候会报错
noCopy noCopy
// [P]poolLocal,表示每个local的P池
local unsafe . Pointer
// local的长度
localSize uintptr
// 也是[P]poolLocal,表示上一个生命周期的local
victim unsafe . Pointer
// victim的长度
victimSize uintptr
// 用于创建新对象方法,get获取不到就会调用创建一个新对象,一般由用户传入
New func () interface {}
}
图2:sync.Pool的数据结构
sync.Pool用法有三种方法,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
//初始化pool对象
var pool sync . Pool
type peter struct {
num int
}
// 创建新对象创建方法
func initPool () {
pool = sync . Pool {
New : func () interface {} {
return & peter { num : rand . Int ()}
},
}
}
func main () {
initPool ()
// 从pool对象池中取对象
p1 := pool . Get ().( * peter )
fmt . Println ( "p1" , p1 . num )
// 将对象放入pool对象池
pool . Put ( p1 )
p2 := pool . Get ().( * peter )
fmt . Println ( "p2" , p2 . num )
}
首先,需要初始化Pool,唯一需要的就是设置好New函数。当调用Get方法时,如果池子里缓存了对象,就直接返回缓存的对象。如果没有存货,则调用New函数创建一个新的对象。
另外,我们发现Get方法取出来的对象和上次Put进去的对象实际上是同一个,Pool没有做任何“清空”的处理。但我们不应当对此有任何假设,因为在实际的并发使用场景中,无法保证这种顺序,最好的做法是在Put前,将对象清空。
2. 单元测试
为了测试Get/Put的功能。我们来看下TestPoolNew:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
func TestPoolNew ( t * testing . T ) {
// disable GC so we can control when it happens.
defer debug . SetGCPercent ( debug . SetGCPercent ( - 1 ))
i := 0
p := Pool {
New : func () interface {} {
i ++
return i
},
}
if v := p . Get (); v != 1 {
t . Fatalf ( "got %v; want 1" , v )
}
if v := p . Get (); v != 2 {
t . Fatalf ( "got %v; want 2" , v )
}
// Make sure that the goroutine doesn't migrate to another P
// between Put and Get calls.
Runtime_procPin ()
p . Put ( 42 )
if v := p . Get (); v != 42 {
t . Fatalf ( "got %v; want 42" , v )
}
Runtime_procUnpin ()
if v := p . Get (); v != 3 {
t . Fatalf ( "got %v; want 3" , v )
}
}
首先设置了GC=-1,作用就是停止GC。函数都跑完了,那为啥要用defer?
注意到,debug.SetGCPercent这个函数被调用了两次,而且这个函数返回的是上一次GC的值。因此,defer在这里的用途是还原到调用此函数之前的GC设置,也就是恢复现场。
调置了Pool的New函数:直接返回一个int,变且每次调用New,都会自增 1。然后,连续调用了两次Get函数,因为这个时候Pool里没有缓存的对象,因此每次都会调用New创建一个,所以第一次返回 1,第二次返回 2。
调用Runtime_procPin()防止 goroutine 被强占,目的是保护接下来的一次Put和Get操作,使得它们操作的对象都是同一个 P 的“池子”。并且,这次调用Get的时候并没有调用New,因为之前有一次Put的操作。
再次调用Get操作,因为没有“存货”,因此还是会再次调用New创建一个对象。
其他TestPool函数:
TestPoolGC和TestPoolRelease则主要测试GC对Pool里对象的影响。这里用了一个函数,用于计数有多少对象会被GC回收:
1
2
3
runtime . SetFinalizer ( v , func ( vv * string ) {
atomic . AddUint32 ( & fin , 1 )
})
TestPoolStress从名字看,主要是想测一下“压力”,具体操作就是起了 10 个 goroutine 不断地向Pool里Put对象,然后又Get对象,看是否会出错。TestPoolDequeue和TestPoolChain,都调用了testPoolDequeue,这是具体干活的。它需要传入一个PoolDequeue接口:
1
2
3
4
5
6
// poolDequeue testing.
type PoolDequeue interface {
PushHead ( val interface {}) bool
PopHead () ( interface {}, bool )
PopTail () ( interface {}, bool )
}
PoolDequeue是一个双端队列,可以从头部入队元素,从头部和尾部出队元素。调用函数时,前者传入NewPoolDequeue(16),后者传入NewPoolChain(),底层其实都是poolDequeue这个结构体。
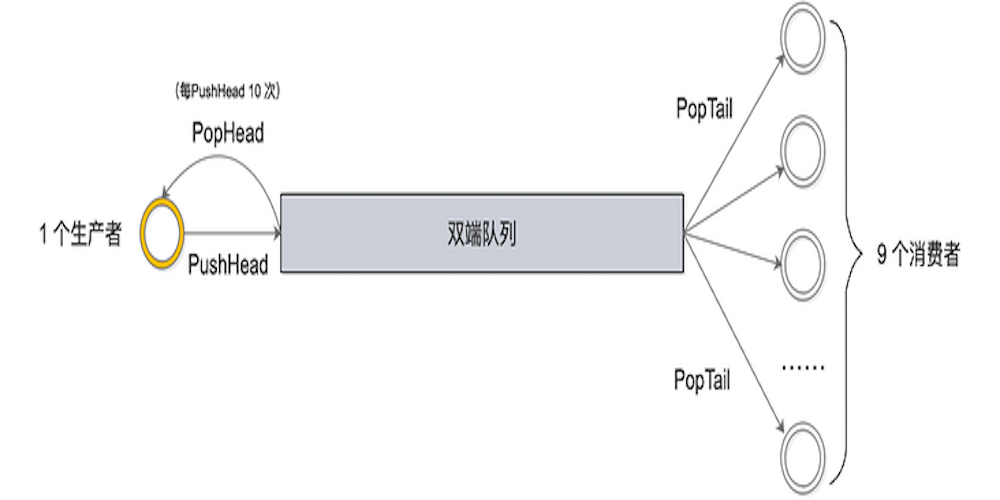
具体testPoolDequeue工作过程如下:
图3:testPoolDequeue工作流程
总共起了 10 个 goroutine:1 个生产者,9 个消费者。生产者不断地从队列头pushHead元素到双端队列里去,并且每 push 10 次,就popHead一次;消费者则一直从队列尾取元素。不论是从队列头还是从队列尾取元素,都会在map里做标记,最后检验每个元素是不是只被取出过一次。
3. 原理结构
当Pool没有缓存的对象时,调用New方法生成一个新的对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
type poolLocal struct {
poolLocalInternal
// 将 poolLocal 补齐至两个缓存行的倍数,防止 false sharing,
// 每个缓存行具有 64 bytes,即 512 bit
// 目前我们的处理器一般拥有 32 * 1024 / 64 = 512 条缓存行
// 伪共享,仅占位用,防止在 cache line 上分配多个 poolLocalInternal
pad [ 128 - unsafe . Sizeof ( poolLocalInternal {}) % 128 ] byte
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
// P 的私有缓存区,使用时无需要加锁
private interface {}
// 公共缓存区。本地 P 可以 pushHead/popHead;其他 P 则只能 popTail
shared poolChain
}
如果没有pad字段,那么当需要访问 0 号索引的poolLocal时,CPU 同时会把 0 号和 1 号索引同时加载到 cpu cache。在只修改 0 号索引的情况下,会让 1 号索引的poolLocal失效。这样,当其他线程想要读取 1 号索引时,发生 cache miss,还得重新再加载,对性能有损。增加一个pad,补齐缓存行,让相关的字段能独立地加载到缓存行就不会出现 false sharding 了。
关于poolChain结构体,是双端队列的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
type poolChain struct {
// 只有生产者会 push to,不用加锁
head * poolChainElt
// 读写需要原子控制。 pop from
tail * poolChainElt
}
type poolChainElt struct {
poolDequeue
// next 被 producer 写,consumer 读。所以只会从 nil 变成 non-nil
// prev 被 consumer 写,producer 读。所以只会从 non-nil 变成 nil
next , prev * poolChainElt
}
type poolDequeue struct {
// The head index is stored in the most-significant bits so
// that we can atomically add to it and the overflow is
// harmless.
// headTail 包含一个 32 位的 head 和一个 32 位的 tail 指针。这两个值都和 len(vals)-1 取模过。
// tail 是队列中最老的数据,head 指向下一个将要填充的 slot
// slots 的有效范围是 [tail, head),由 consumers 持有。
headTail uint64
// vals 是一个存储 interface{} 的环形队列,它的 size 必须是 2 的幂
// 如果 slot 为空,则 vals[i].typ 为空;否则,非空。
// 一个 slot 在这时宣告无效:tail 不指向它了,vals[i].typ 为 nil
// 由 consumer 设置成 nil,由 producer 读
vals [] eface
}
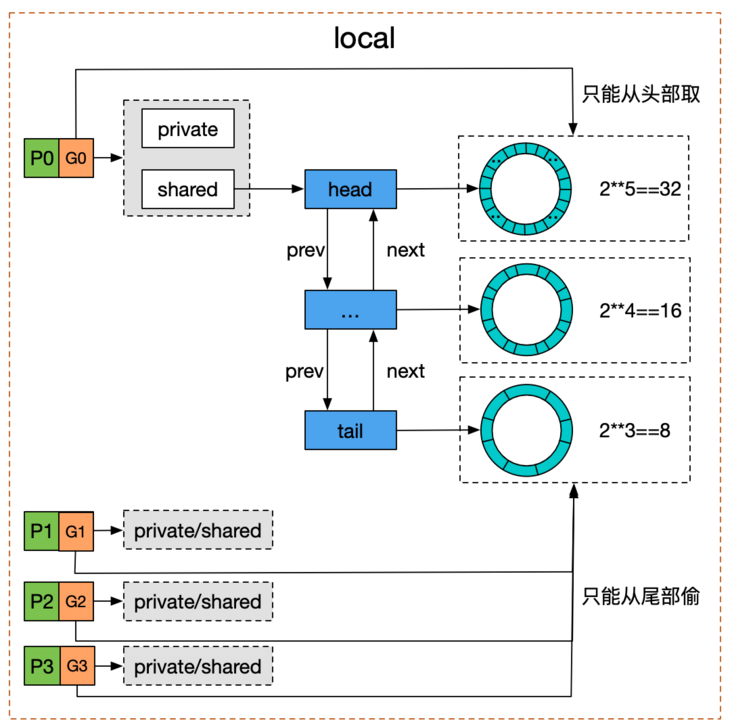
poolDequeue 被实现为单生产者、多消费者的固定大小的无锁(atomic实现) Ring式队列(底层存储使用数组,使用两个指针标记head、tail)。生产者可以从head插入、head删除,而消费者仅可从tail删除。headTail指向队列的头和尾,通过位运算将head和tail存入headTail变量中。
对于双端队列 的理解:
图4:双端队列
我们看到Pool并没有直接使用poolDequeue,原因是它的大小是固定的,而Pool的大小是没有限制的。因此,在poolDequeue之上包装了一下,变成了一个poolChainElt的双向链表,可以动态增长。(摘录于segmentFault )
3. semaphore
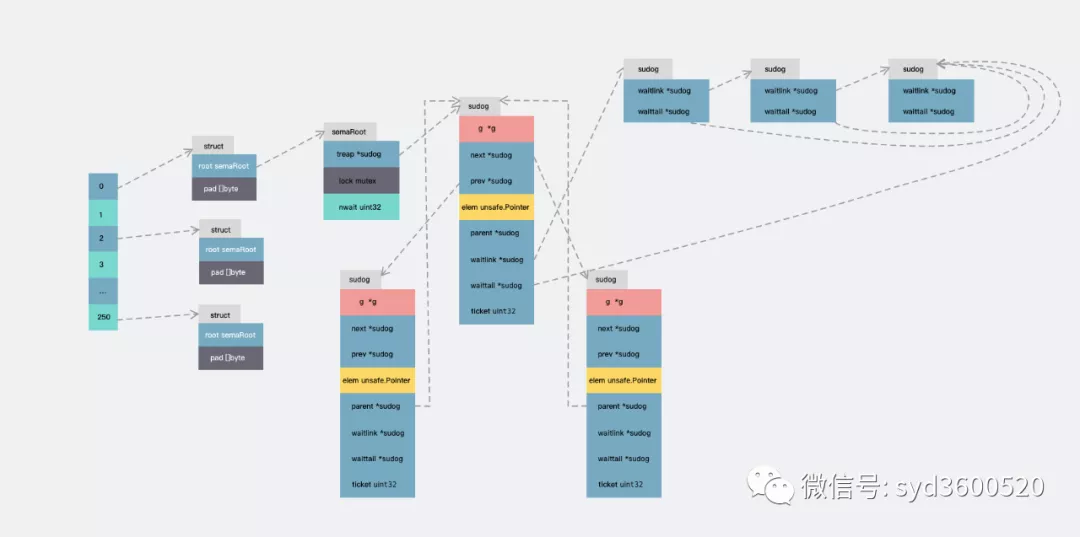
1. 数据结构
sema.go中定义了一个全局变量,semtable数组。大小为251,元素为一个匿名结构体。这里为了避免伪共享问题做了一下内存填充。
1
2
3
4
5
6
7
// Prime to not correlate with any user patterns.
const semTabSize = 251
var semtable [ semTabSize ] struct {
root semaRoot
pad [ cpu . CacheLinePadSize - unsafe . Sizeof ( semaRoot {})] byte
}
每个元素持有的semaRoot为这个数据结构的核心。
1
2
3
4
5
6
7
// 为sync.Mutex准备的异步信号量
// golang.org/issue/17953 可以查看引入二级列表之前性能较差的程序示例test/locklinear.go
type semaRoot struct {
lock mutex
treap * sudog // 平衡树的根节点
nwait uint32 // Number of waiters. Read w/o the lock.
}
semaRoot的结构看上去并不复杂,每个semaRoot持有一个具有不同地址(sudog.elem)的sudog平衡树,每个sudog都可以通过s.waitlink依次指向一个相同地址等待的sudog列表, 在具有相同等待地址的sudog内部列表上的操作时间复杂度都是$O(1)$。顶层semaRoot列表的扫描为$O(\log n)$,其中$n$是阻止goroutines的不同信号量地址的数量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
type sudog struct {
g * g
next * sudog
prev * sudog
elem unsafe . Pointer //数据元素 (可能指向栈)
// 下面的字段不会并发访问
// 对于channels, waitlink 只被g访问
// 对于semaphores, 所有自动(包括上面的)只有获取semaRoot的锁才能被访问
acquiretime int64
releasetime int64
ticket uint32
//isSelect表示g正在参与一个select,因此必须对g.selectDone进行CAS才能赢得唤醒竞争
isSelect bool
//success表示channel c上的通信是否成功。如果goroutine因为在通道c上传递了一个值而被唤醒,则为true;
//如果因为channel c关闭而被唤醒,则为false
success bool
parent * sudog // semaRoot binary tree
waitlink * sudog // g.waiting list or semaRoot
waittail * sudog // semaRoot
c * hchan // channel
}
这里可能就涉及到了Go的运行时调度的知识:
sudog是对goroutine的一种封装,比如当你使用channel时,goroutine在sending/receiving阻塞时是被封装成sudog放进阻塞队列进行等待。sudog是必需的,因为g和同步对象的关系是多对多的。一个g可以出现在许多等待列表上,因此一个g可能有很多个sudog。并且许多g可能正在等待同一个同步对象,因此一个对象可能有许多sudogsudog是从一个特殊的pool中分配。使用acquireSudog和releaseSudog来分配和释放他们。
其中的next、prev、parent字段构成了平衡树,waitlink和waittail构成了相同信号量地址的链表结构。
图5:sudog涉及的链表结构
关于源码分析,我会在另一篇文章提到。
4 sync.Once
1. sync.Once 用法
sync.Once是 Golang package 中使方法只执行一次的对象实现,作用与init函数类似。但也有所不同。
init函数是在文件包首次被加载的时候执行,且只执行一次sync.Once 是在代码运行中需要的时候执行,且只执行一次
当一个函数不希望程序在一开始的时候就被执行的时候,我们可以使用sync.Once。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package main
import (
"fmt"
"sync"
)
func main () {
var once sync . Once
onceBody := func () {
fmt . Println ( "Only once" )
}
done := make ( chan bool )
for i := 0 ; i < 10 ; i ++ {
go func () {
once . Do ( onceBody )
done <- true
}()
}
for i := 0 ; i < 10 ; i ++ {
<- done
}
}
# Output :
Only once
在多数情况下,sync.Once被用于控制变量的初始化,这个变量的读写通常遵循单例模式,满足这三个条件:
当且仅当第一次读某个变量时,进行初始化(写操作)
变量被初始化过程中,所有读都被阻塞(读操作;当变量初始化完成后,读操作继续进行
变量仅初始化一次,初始化完成后驻留在内存里
需要注意的点:
Once常常用来初始化单例资源,或者并发访问只需初始化一次的共享资源,或者在测试的时候初始化一次测试资源。sync.Once只暴露了一个方法Do,你可以多次调用Do方法,但是只有第一次调用Do方法时f参数才会执行,这里的f是一个无参数无返回值的函数。
2. 原理结构
Once的结构体:
1
2
3
4
type Once struct {
done uint32 // 初始值为0表示还未执行过,1表示已经执行过
m Mutex
}
其中,done成员变量:
1 表示资源未初始化,需要进一步初始化
0 表示资源已初始化,无需初始化,直接返回即可
m成员变量:
为了防止多个goroutine调用doSlow()初始化资源时,造成资源多次初始化,因此采用Mutex锁机制来保证有且仅初始化一次
Once所拥有的方法Do和doSlow:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func ( o * Once ) Do ( f func ()) {
// 判断done是否为0,若为0,表示未执行过,调用doSlow()方法初始化
if atomic . LoadUint32 ( & o . done ) == 0 {
// Outlined slow-path to allow inlining of the fast-path.
o . doSlow ( f )
}
}
// 加载资源
func ( o * Once ) doSlow ( f func ()) {
o . m . Lock ()
defer o . m . Unlock ()
// 采用双重检测机制 加锁判断done是否为零
if o . done == 0 {
// 执行完f()函数后,将done值设置为1
defer atomic . StoreUint32 ( & o . done , 1 )
// 执行传入的f()函数
f ()
}
调用Do函数时,首先判断done值是否为0,若为1,表示传入的匿名函数f()已执行过,无需再次执行;若为0,表示传入的匿名函数f()还未执行过,则调用doSlow()函数进行初始化。
在doSlow()函数中,若并发的goroutine进入该函数中,为了保证仅有一个goroutine执行f()匿名函数。为此,需要加互斥锁保证只有一个goroutine进行初始化,同时采用了双检查的机制(double-checking) ,再次判断o.done是否为0,如果为0,则是第一次执行,执行完毕后,就将o.done设置为 1,然后释放锁。
即使此时有多个 goroutine 同时进入了doSlow方法,因为双检查的机制,后续的 goroutine 会看到o.done的值为 1,也不会再次执行f。
这样既保证了并发的 goroutine 会等待f完成,而且还不会多次执行f。